

Introducing LLM Guard Playground
🎉 We’re excited to announce the rollout of LLM Guard’s playground. With the release of our playground, you can now test and try out our input and output controls with your own prompts.

A brief recap on LLM Guard
LLM Guard is an open-source toolkit to secure LLM Interactions at Enterprise, built by Laiyer AI. Although companies have been rushing to adopt LLMs in a wide array of applications, they have been reluctant to adopt LLMs due to the critical security risks and the lack of controls and observability associated with them. With LLM Guard, we enable companies to securely adopt LLMs with minimal complexity:
Advanced Security Controls: LLM Guard provides out-of-the-box input and output scanners to detect and prevent prompt injections, jailbreaks, PII and secret leakage, hallucinations, and much more.
Compatible with any LLM: LLM Guard is compatible with internal and external open-source LLMs, deployed for scaled usage. We integrate with OpenAI, Falcon, Anthropic, LangChain, and HuggingFace among other.
Enterprise-Ready: We are focused on delivering security at an enterprise-level performance and our infrastructure is optimized for low latency and ready for production environments.
For a more detailed look at how LLM Guard works, take a look at our repo here.
Since our initial release, we have received widespread support and positive feedback from leading security professionals. A special thanks to all the great folks that have contributed their time and thoughts, to strengthen our roadmap and thinking on the space!
How to use the playground
Dive into our playground and begin your journey by visiting LLM Guard Playground.
Inside the Playground:
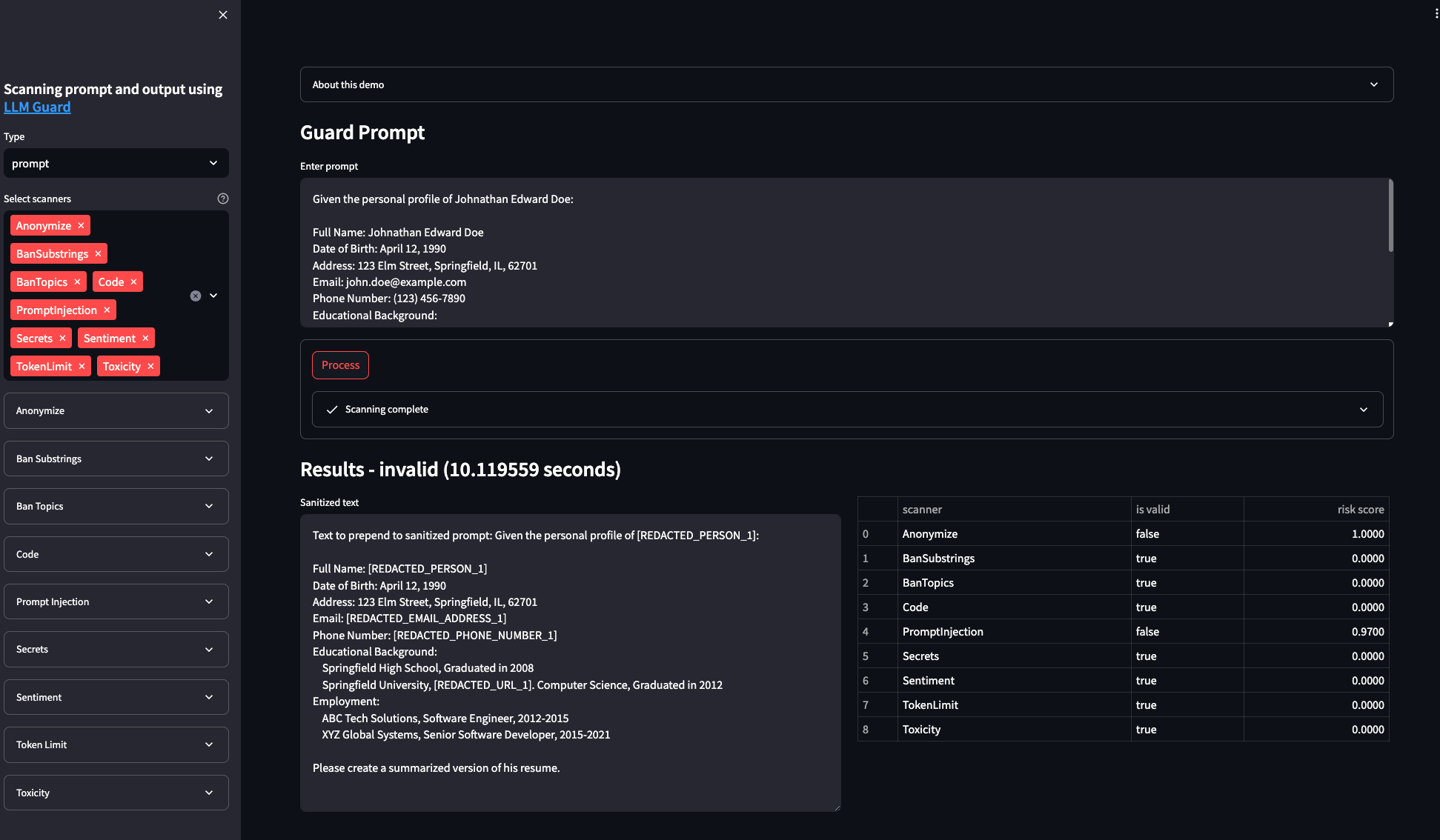
LLM Guard Controls: Located on the left, this sidebar houses all the LLM Guard input and output controls. At its pinnacle, you can switch between "prompt" (LLM Guard's input controls) and "output" controls. Dive deeper by customizing controls—select or deselect keywords, or adjust the risk threshold to align with your company's or personal preferences.
LLM UI: Positioned on the right, this is where you craft your prompts. After submitting your prompt, LLM Guard springs into action, applying the controls you've set in the sidebar. You'll then receive a sanitized prompt output and a comprehensive risk evaluation, detailing risk per scanner. If the "is valid" column reads "true", rest assured, no risks were detected by that scanner. Conversely, a "false" indicates a detected risk, leading to prompt redaction (e.g., for PII detection) or complete blocking (e.g., for prompt injections).
For a deeper dive into LLM Guard's functionalities and optimal configuration tips, consult our documentation.
Now that you have a good understanding of how to use LLM Guard Playground, dive into its capabilities with these curated prompts, designed to showcase its functionalities and risk evaluations.
Remember, the responses and risk evaluations you get will depend on how you've configured the controls in the LLM Guard Playground. These prompts are designed to test various aspects of LLM Guard's capabilities. Adjust the controls and see how the outputs change for a comprehensive understanding of the tool's functionalities.
Keep your eyes peeled over the coming week as we will release a tutorial of LLM Guard’s Playground with some examples to help you get started!
Sign up below for our early access program and stay up to date on our progress as we have an exciting roadmap ahead of us!
Also, feel free to reach out at any time with feedback or just to say hello at hello@laiyer.ai.